11:47 a.m. A paint shop in Ranchi.
The fan is loud. A truck reverses outside. The dealer is on WhatsApp, half in Hindi, half in Bhojpuri, calling out a shade code he can only half remember.
"Woh 8434 ka mat finish... do dabba, aur ek peti white primer".
Or 8344. Or 8443. Three real codes that sound the same.
Only one is on his price list.
The voice AI has to be right the first time. Not "did its best". Right.
Here's my thesis: voice ordering doesn't fail at the microphone. It fails at the catalog.
The hard part isn't hearing him. It's figuring out which SKU, in which unit, on his price list.
Transcription is the easy 30%.
Demos run in quiet rooms. A trained narrator. Crisp audio. Everyone claps.
Now try the same demo in a shop.
Two fans. A delivery argument. A dealer switching mid-sentence between three languages and a code from memory.
The benchmarks already tell you what happens. Mixing Hindi and English makes the same model 30 - 50% more wrong. Add babble noise and the errors triple. Two voices at once, half the words come out wrong.
That's the floor. Not the ceiling.
Transcription is not understanding. It's dictation under good conditions.
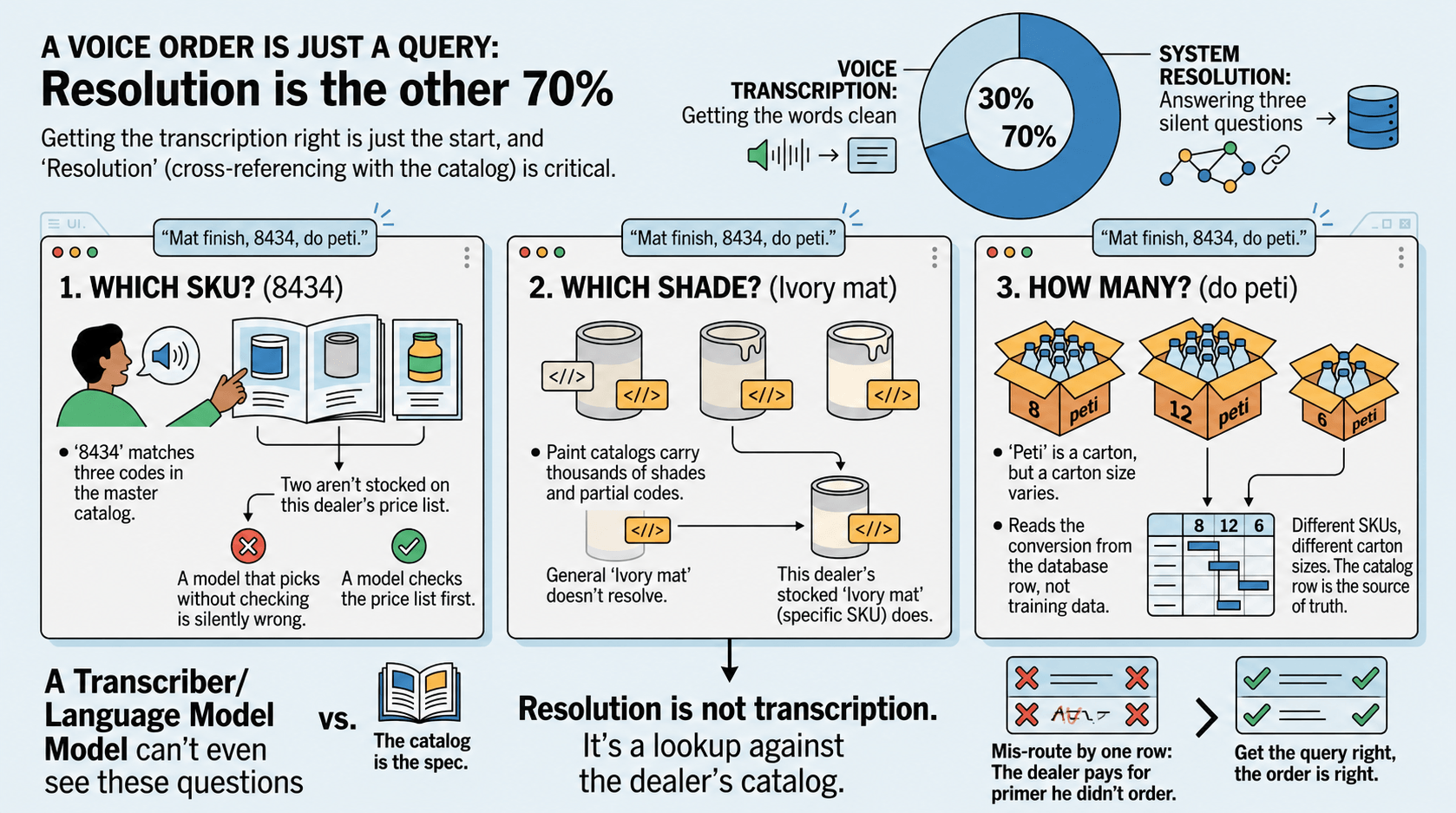
Resolution is the other 70%.
Assume the words came through clean. "Mat finish, 8434, do peti".
The system still has to answer three questions.
Which SKU? "8434" matches three codes. Two aren't on this dealer's price list. Pick the wrong one and you ship the wrong product, silently.
Which shade? Thousands of shades. Partial codes. Old names some dealers still use. "Ivory mat" doesn't resolve. This dealer's stocked "Ivory mat" does.
How many? Peti is a carton. But a carton isn't always twelve. One row says 8. Another says 12. A third says 6. The catalog defines the conversion. The model has to read it.
The catalog is the spec. The voice is just a question asked against it.
Resolution is not transcription. It's a lookup against the dealer's catalog.
Get it right, the order is right. Miss by one row, the dealer pays for primer he didn't order.
The catalog is the work. The model is the interpreter.
This is where most generative AI pilots die.
We built R10 around the catalog. The speech layer is tuned for noisy shops, not airport announcements. The resolution layer reads the dealer's price list. Then the catalog's conversion. Then it drafts the order.
A human confirms in one tap.
The model isn't doing the resolution. The catalog is.
That swap is the whole product. It's also the part nobody demos.
Long story short,
Eight minutes on a phone call.
Now thirty seconds on a voice note.
Voice ordering is a catalog problem wearing a microphone costume.
Eight minutes to thirty seconds isn't a faster speech model. It's a smarter catalog underneath.


